🐶 I Built a Core Banking System in COBOL
I built a core banking system from scratch in COBOL. It has 25 modules, 612 passing tests, double-entry general ledger accounting, ACH and wire transfer processing, interest accrual across four day-count conventions, BSA/AML compliance with CTR and SAR filing, Reg CC hold calculation using business day arithmetic, and a batch processing layer that runs end-of-day and end-of-month cycles.
It is called VAULT-CBS. One person, mass-delegating to AI agents, two days.
Feb 26 10:32 🥂 Implement VAULT-CBS core banking system with full test suite
Feb 26 11:16 🦄 Production hardening: overflow protection, persistence, audit, SAR
Feb 26 11:36 🤑 Audit round 1: fix ACHRECV0 bugs, EODPROC0 gaps, Reg CC exceptions
...
Feb 26 22:59 🔨 R38: FEECALC0 inactive error code + GLPOST0 negative amount guard
Feb 26 23:09 🔨 R39: HOLDCALC0 boundary + DISPMGT0 denied-dispute coverage
Feb 28 07:31 🔧 R40: Fix all 8 open bugs — LOANPMT0 + ODMGMT0 + EOMPROC0 + WIREXFR0
Feb 28 07:39 ✅ R41: LOANPMT0 late fee flag fix — final audit round (611→612)
One of my Claude Code sessions ran for over 22 hours straight. By sheer luck, Anthropic reset everyone’s usage limits right after because of a bug on their end.
Thank god I ran this yesterday🤣 pic.twitter.com/nqkOo1wTnY
— Kevin (@_KevinTang) February 27, 2026
The Methodology
Here is the part I actually care about.
Everyone doing AI-assisted development right now is focused on one artifact: the code. You prompt an agent, it writes code, you check if the code works, you iterate. The code is the thing.
I think this is wrong, or at least incomplete. The approach I used for VAULT-CBS treats the code as the least important artifact in the project. The two things that actually matter are the spec and the test suite. I have been calling this Regenerable Implementation: you write comprehensive specs and comprehensive tests, and then the implementation becomes a regenerable artifact that AI agents can produce, throw away, and reproduce.
The spec defines what the system should do. The test suite defines how you know it does it. The code is just whatever makes the tests pass. If you deleted every .cbl source file in VAULT-CBS and kept only the specs and the 612 tests, an AI agent could regenerate a working implementation. I know this because that is basically what happened — the initial 25 modules were generated from specs, and then 41 rounds of auditing rewrote large chunks of them while the test suite kept everything honest.
This is not test-driven development in the traditional sense. TDD says write a test, write the minimum code to pass it, refactor, repeat. That is a fine methodology for a human typing code. But when your implementation engine is an AI agent that can produce 500 lines in seconds, the bottleneck is not writing code. The bottleneck is knowing whether the code is correct. And the only way to know that at scale is to have tests that are more authoritative than the code itself.
So the workflow looks like this:
- Write a detailed spec for a module. What are the inputs, outputs, edge cases, regulatory requirements, error conditions.
- Write tests that encode those requirements. Not five happy-path tests. Dozens of tests that cover the boundary conditions, the error paths, the interactions with other modules.
- Point an AI agent at the spec and tell it to make the tests pass.
- Run the tests. Fix what fails. Add tests for anything the agent got wrong that you did not anticipate.
- Repeat steps 3-4, or throw away the implementation entirely and regenerate from scratch.
The spec and tests are the durable assets. The implementation is disposable. This is a different mental model from how most people write software, where the code is precious and the tests are an afterthought. Here, the code is the afterthought.
Why COBOL, Why Banking
COBOL processes the vast majority of the world’s financial transactions. The core ledger at JPMorgan Chase, Bank of America, Wells Fargo, and most other large banks runs on COBOL systems originally written decades ago. These are not legacy artifacts waiting to be replaced. They are the production systems of record.
I wanted to understand what is actually inside one of these systems. Not at the hand-wavy architecture diagram level, but at the level where you have to decide: when a customer deposits a $5,000 check on a Friday, how many business days do you hold it? Does the answer change if the check is drawn on a non-local bank? What if it is a Treasury check? What if the account is less than 30 days old?
The answers are in Regulation CC. Local checks get a 2-business-day hold. Non-local checks get 5. Exception items, which include new accounts and checks over $5,525, can be held for 7. And “business day” does not mean what you think it means. Federal holidays are not business days. Weekends are not business days. So a Friday deposit with a 2-day hold releases on Tuesday, unless Monday is a holiday, in which case it releases on Wednesday.
I could have learned this from reading the regulation. But building the system that implements it forced me to confront every ambiguity the regulation leaves open.
Banking also turns out to be a perfect domain for testing Regenerable Implementation. The domain rules are complex but well-documented. The correctness criteria are unambiguous — either the hold releases on the right day or it does not, either the GL balances or it does not. And the stakes of getting it wrong are concrete: real money moves incorrectly. You cannot hand-wave your way past a test that checks whether a loan payment split between interest and principal produces a negative accrued interest balance.
The Domain Is the Hard Part
The technical implementation of a banking system is straightforward. You have accounts with balances. Transactions move money between them. A general ledger tracks debits and credits. Interest accrues daily and gets paid monthly. Fees get assessed. Reports get filed.
None of this is algorithmically complex. There are no graph algorithms, no dynamic programming, no machine learning models. The data structures are flat records. The control flow is sequential. A CS freshman could understand any individual paragraph of the code.
The difficulty is in the domain rules. Every operation has edge cases driven by regulations, accounting standards, or operational risk controls, and those edge cases interact with each other.
Here is an example. When you post a transaction that reduces an account balance, you need to:
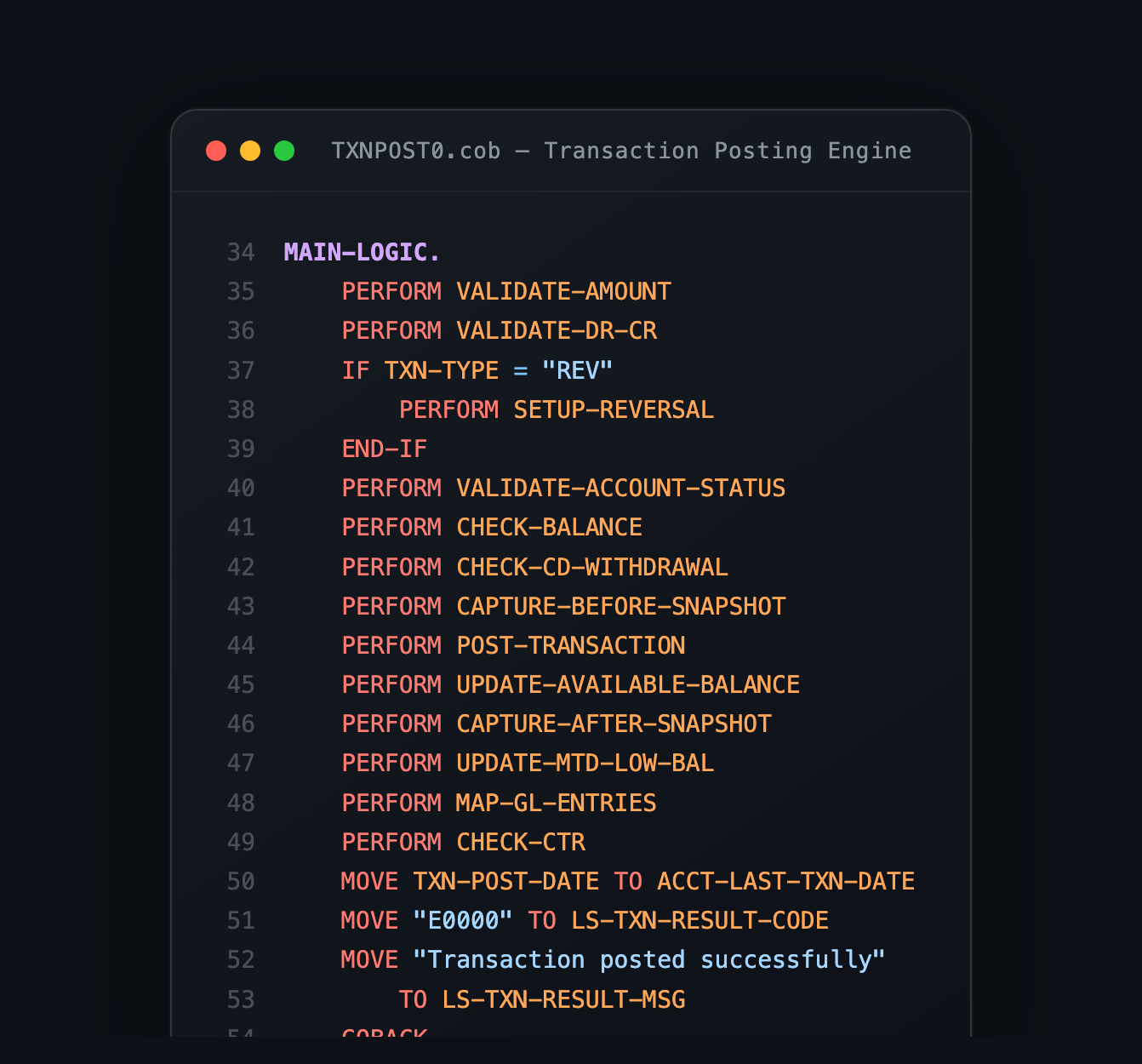
- Check if the account is active, closed, frozen, dormant, restricted, or escheated. Each status blocks different operations. Closed and frozen block everything. Dormant and restricted block debits but allow credits. Escheated accounts are turned over to the state.
- Check if there are sufficient funds, accounting for the ledger balance, hold amounts, and any available credit.
- If funds are insufficient, check if the account has overdraft protection, and if so, whether the overdraft limit covers the shortfall, and if so, charge an OD fee.
- If there is no overdraft protection, return an NSF code and charge an NSF fee, but cap the fee at a daily maximum to comply with consumer protection rules.
- Update the ledger balance, the available balance, the month-to-date low balance watermark (needed later for fee waiver calculations), and the last transaction date (needed for dormancy detection).
- Generate the corresponding GL entries: debit one account, credit another, always balanced.
- If the transaction is cash, aggregate it toward the daily Currency Transaction Report threshold ($10,000).
- If the account is a savings or money market account, increment the Reg D transfer counter and check against the monthly limit.
- Write an audit record with before and after images.
Each of those steps is simple. The code for any one of them is 5-10 lines of COBOL. But the interaction surface between all of them is where the bugs live. And this is exactly why the test suite matters more than the implementation. The implementation of step 3 is trivial. Knowing that you need to test step 3 in combination with step 1 (what if the account is restricted AND has overdraft protection?) and step 4 (what if OD and NSF trigger on the same transaction?) — that is the actual engineering work.
The Audit Cycle
After the initial build, I ran 41 rounds of automated audits. Each round consisted of spawning AI agents to review the source code for bugs, missing error handling, regulatory gaps, and inconsistencies between modules. The agents would file findings, I would triage them as real bugs or false positives, fix the real ones, write tests for the fixes, and run the full suite to make sure nothing regressed.
This is Regenerable Implementation in practice. The audit agents are not just reviewing code. They are comparing the implementation against the spec and the test suite, finding places where the three disagree. When you find a disagreement, you have to decide: is the spec wrong, is the test wrong, or is the code wrong? Usually it is the code, because the spec and tests were written with more care.
The first few rounds caught obvious problems. No overflow protection anywhere. The hold release date was never actually computed, it just copied the deposit date. The 30/360 day-count convention used the same logic as Actual/360.
The later rounds caught subtler things. A DIVIDE statement in the loan payment module used the same variable for both GIVING and REMAINDER, which is undefined behavior in the COBOL standard. GnuCOBOL happens to write REMAINDER last, so the leap year check worked. But a compiler update could reverse the order and silently break February 29th handling.
Another: the fee calculation engine requires both an account-level waiver code and a fee-schedule-level waiver flag to trigger a waiver. The end-of-month batch was setting the account waiver code but never setting the fee-schedule flag. Every customer who qualified for a direct deposit or employee fee waiver was being incorrectly charged through the monthly batch.
Another: when a loan payment is split between accrued interest and principal, the accrued interest field has 6 decimal places but the payment split rounds to 2. If rounding pushes the 2-decimal value above the 6-decimal value (100.005678 rounds to 100.01), subtracting the rounded amount from the 6-decimal field produces a negative balance. That negative accrued interest silently propagates to future interest calculations and payoff quotes.
None of these are the kind of bugs you find with unit tests that check the happy path. They are the kind of bugs that surface when you have enough test coverage to explore the interaction between subsystems, and enough audit pressure to look at the code from angles you did not think of when writing it.
The test suite grew from about 170 tests after the initial build to 612 after 41 rounds. Every bug fix came with a test that reproduced the bug first, then verified the fix. The full suite runs in a few seconds. That fast feedback loop is what makes the whole methodology work — you can regenerate, audit, fix, and verify in minutes, not days.
What COBOL Gets Right
COBOL is a deeply unfashionable language. The syntax is verbose. The tooling is dated. Nobody writes new COBOL by choice.
But there is a reason it has survived in financial systems for 60 years, and it is not just institutional inertia. COBOL has two properties that matter enormously for banking.
First, fixed-point decimal arithmetic. COBOL does not have floating-point numbers. You declare PIC S9(13)V99 and you get a signed number with 13 integer digits and 2 decimal places. Arithmetic on these fields is exact. There is no 0.1 + 0.2 = 0.30000000000000004 problem. Money is stored and computed exactly as dollars and cents, because the language was designed for exactly this.
Second, the ON SIZE ERROR clause. Every arithmetic operation can include an ON SIZE ERROR handler that fires if the result exceeds the field’s capacity. This is not an exception. It is not a trap. It is an explicit, in-line control flow branch that keeps the original field value intact and lets you handle the overflow however you want. In VAULT-CBS, every balance-mutating operation uses this to prevent silent corruption at the $99 trillion boundary.
These are not features you appreciate until you have tried implementing the same thing in a language without them. In most languages, you would need a decimal library and manual overflow checks on every arithmetic operation. In COBOL, they are built into the language.
What I Learned
Building a core banking system taught me a few things.
The reason these systems are hard to replace is not the language. It is the accumulated domain logic. Thousands of edge cases in how money moves, how dates work, how regulations interact, how errors propagate, how audit trails must be maintained. A rewrite in any language still has to implement all of this, and the people who understand all the rules are the same people who have been maintaining the COBOL for decades. I wrote about this in Backwards Compatible for Life.
Banking is not a technology problem. It is a regulatory compliance problem with a technology implementation. Every feature I built was shaped more by the relevant regulation than by any technical constraint. Reg CC determined hold calculation. Reg D determined transfer limits. Reg E determined dispute timelines. BSA/AML determined transaction monitoring thresholds. The code is just the regulation in executable form.
But the biggest takeaway is about methodology, not banking. Verification is everything. Writing the initial 25 modules took a fraction of the total effort. The other 85% was audit, testing, and fixing the interactions between those modules. If I had stopped after the initial build, I would have had a system that looked complete but silently corrupted money in edge cases.
The gap between “works on the happy path” and “handles real-world inputs correctly” is enormous. In traditional development, you close that gap by writing code carefully. In Regenerable Implementation, you close it by writing specs and tests carefully, and then letting agents regenerate the code until the tests pass. The care moves from the implementation to the verification. I think that shift is going to define how serious software gets built with AI agents.
The code is on GitHub. All 32,000 lines of it.
I built a core banking system from scratch in COBOL. It has 25 modules, 612 passing tests, double-entry general ledger accounting, ACH and wire transfer processing, interest accrual across four day-count conventions, BSA/AML compliance with CTR and SAR filing, Reg CC hold calculation using business day arithmetic, and a batch processing layer that runs end-of-day and end-of-month cycles.
It is called [VAULT-CBS](https://github.com/NSEvent/cobol-banking-system). One person, mass-delegating to AI agents, two days.
```
Feb 26 10:32 🥂 Implement VAULT-CBS core banking system with full test suite
Feb 26 11:16 🦄 Production hardening: overflow protection, persistence, audit, SAR
Feb 26 11:36 🤑 Audit round 1: fix ACHRECV0 bugs, EODPROC0 gaps, Reg CC exceptions
...
Feb 26 22:59 🔨 R38: FEECALC0 inactive error code + GLPOST0 negative amount guard
Feb 26 23:09 🔨 R39: HOLDCALC0 boundary + DISPMGT0 denied-dispute coverage
Feb 28 07:31 🔧 R40: Fix all 8 open bugs — LOANPMT0 + ODMGMT0 + EOMPROC0 + WIREXFR0
Feb 28 07:39 ✅ R41: LOANPMT0 late fee flag fix — final audit round (611→612)
```

One of my Claude Code sessions ran for over 22 hours straight. By sheer luck, Anthropic reset everyone's usage limits right after because of a bug on their end.
<blockquote class="twitter-tweet"><p lang="en" dir="ltr">Thank god I ran this yesterday🤣 <a href="https://t.co/nqkOo1wTnY">pic.twitter.com/nqkOo1wTnY</a></p>— Kevin (@_KevinTang) <a href="https://twitter.com/_KevinTang/status/2027450718664400937?ref_src=twsrc%5Etfw">February 27, 2026</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
## The Methodology
Here is the part I actually care about.
Everyone doing AI-assisted development right now is focused on one artifact: the code. You prompt an agent, it writes code, you check if the code works, you iterate. The code is the thing.
I think this is wrong, or at least incomplete. The approach I used for VAULT-CBS treats the code as the least important artifact in the project. The two things that actually matter are the spec and the test suite. I have been calling this Regenerable Implementation: you write comprehensive specs and comprehensive tests, and then the implementation becomes a regenerable artifact that AI agents can produce, throw away, and reproduce.
The spec defines what the system should do. The test suite defines how you know it does it. The code is just whatever makes the tests pass. If you deleted every `.cbl` source file in VAULT-CBS and kept only the specs and the 612 tests, an AI agent could regenerate a working implementation. I know this because that is basically what happened — the initial 25 modules were generated from specs, and then 41 rounds of auditing rewrote large chunks of them while the test suite kept everything honest.
This is not test-driven development in the traditional sense. TDD says write a test, write the minimum code to pass it, refactor, repeat. That is a fine methodology for a human typing code. But when your implementation engine is an AI agent that can produce 500 lines in seconds, the bottleneck is not writing code. The bottleneck is knowing whether the code is correct. And the only way to know that at scale is to have tests that are more authoritative than the code itself.
So the workflow looks like this:
1. Write a detailed spec for a module. What are the inputs, outputs, edge cases, regulatory requirements, error conditions.
2. Write tests that encode those requirements. Not five happy-path tests. Dozens of tests that cover the boundary conditions, the error paths, the interactions with other modules.
3. Point an AI agent at the spec and tell it to make the tests pass.
4. Run the tests. Fix what fails. Add tests for anything the agent got wrong that you did not anticipate.
5. Repeat steps 3-4, or throw away the implementation entirely and regenerate from scratch.
The spec and tests are the durable assets. The implementation is disposable. This is a different mental model from how most people write software, where the code is precious and the tests are an afterthought. Here, the code is the afterthought.
## Why COBOL, Why Banking
COBOL processes the vast majority of the world's financial transactions. The core ledger at JPMorgan Chase, Bank of America, Wells Fargo, and most other large banks runs on COBOL systems originally written decades ago. These are not legacy artifacts waiting to be replaced. They are the production systems of record.
I wanted to understand what is actually inside one of these systems. Not at the hand-wavy architecture diagram level, but at the level where you have to decide: when a customer deposits a $5,000 check on a Friday, how many business days do you hold it? Does the answer change if the check is drawn on a non-local bank? What if it is a Treasury check? What if the account is less than 30 days old?
The answers are in Regulation CC. Local checks get a 2-business-day hold. Non-local checks get 5. Exception items, which include new accounts and checks over $5,525, can be held for 7. And "business day" does not mean what you think it means. Federal holidays are not business days. Weekends are not business days. So a Friday deposit with a 2-day hold releases on Tuesday, unless Monday is a holiday, in which case it releases on Wednesday.
I could have learned this from reading the regulation. But building the system that implements it forced me to confront every ambiguity the regulation leaves open.
Banking also turns out to be a perfect domain for testing Regenerable Implementation. The domain rules are complex but well-documented. The correctness criteria are unambiguous — either the hold releases on the right day or it does not, either the GL balances or it does not. And the stakes of getting it wrong are concrete: real money moves incorrectly. You cannot hand-wave your way past a test that checks whether a loan payment split between interest and principal produces a negative accrued interest balance.
## The Domain Is the Hard Part
The technical implementation of a banking system is straightforward. You have accounts with balances. Transactions move money between them. A general ledger tracks debits and credits. Interest accrues daily and gets paid monthly. Fees get assessed. Reports get filed.
None of this is algorithmically complex. There are no graph algorithms, no dynamic programming, no machine learning models. The data structures are flat records. The control flow is sequential. A CS freshman could understand any individual paragraph of the code.
The difficulty is in the domain rules. Every operation has edge cases driven by regulations, accounting standards, or operational risk controls, and those edge cases interact with each other.
Here is an example. When you post a transaction that reduces an account balance, you need to:

1. Check if the account is active, closed, frozen, dormant, restricted, or escheated. Each status blocks different operations. Closed and frozen block everything. Dormant and restricted block debits but allow credits. Escheated accounts are turned over to the state.
2. Check if there are sufficient funds, accounting for the ledger balance, hold amounts, and any available credit.
3. If funds are insufficient, check if the account has overdraft protection, and if so, whether the overdraft limit covers the shortfall, and if so, charge an OD fee.
4. If there is no overdraft protection, return an NSF code and charge an NSF fee, but cap the fee at a daily maximum to comply with consumer protection rules.
5. Update the ledger balance, the available balance, the month-to-date low balance watermark (needed later for fee waiver calculations), and the last transaction date (needed for dormancy detection).
6. Generate the corresponding GL entries: debit one account, credit another, always balanced.
7. If the transaction is cash, aggregate it toward the daily Currency Transaction Report threshold ($10,000).
8. If the account is a savings or money market account, increment the Reg D transfer counter and check against the monthly limit.
9. Write an audit record with before and after images.
Each of those steps is simple. The code for any one of them is 5-10 lines of COBOL. But the interaction surface between all of them is where the bugs live. And this is exactly why the test suite matters more than the implementation. The implementation of step 3 is trivial. Knowing that you need to test step 3 in combination with step 1 (what if the account is restricted AND has overdraft protection?) and step 4 (what if OD and NSF trigger on the same transaction?) — that is the actual engineering work.
## The Audit Cycle
After the initial build, I ran 41 rounds of automated audits. Each round consisted of spawning AI agents to review the source code for bugs, missing error handling, regulatory gaps, and inconsistencies between modules. The agents would file findings, I would triage them as real bugs or false positives, fix the real ones, write tests for the fixes, and run the full suite to make sure nothing regressed.
This is Regenerable Implementation in practice. The audit agents are not just reviewing code. They are comparing the implementation against the spec and the test suite, finding places where the three disagree. When you find a disagreement, you have to decide: is the spec wrong, is the test wrong, or is the code wrong? Usually it is the code, because the spec and tests were written with more care.
The first few rounds caught obvious problems. No overflow protection anywhere. The hold release date was never actually computed, it just copied the deposit date. The 30/360 day-count convention used the same logic as Actual/360.
The later rounds caught subtler things. A DIVIDE statement in the loan payment module used the same variable for both GIVING and REMAINDER, which is undefined behavior in the COBOL standard. GnuCOBOL happens to write REMAINDER last, so the leap year check worked. But a compiler update could reverse the order and silently break February 29th handling.
Another: the fee calculation engine requires both an account-level waiver code and a fee-schedule-level waiver flag to trigger a waiver. The end-of-month batch was setting the account waiver code but never setting the fee-schedule flag. Every customer who qualified for a direct deposit or employee fee waiver was being incorrectly charged through the monthly batch.
Another: when a loan payment is split between accrued interest and principal, the accrued interest field has 6 decimal places but the payment split rounds to 2. If rounding pushes the 2-decimal value above the 6-decimal value (100.005678 rounds to 100.01), subtracting the rounded amount from the 6-decimal field produces a negative balance. That negative accrued interest silently propagates to future interest calculations and payoff quotes.
None of these are the kind of bugs you find with unit tests that check the happy path. They are the kind of bugs that surface when you have enough test coverage to explore the interaction between subsystems, and enough audit pressure to look at the code from angles you did not think of when writing it.
The test suite grew from about 170 tests after the initial build to 612 after 41 rounds. Every bug fix came with a test that reproduced the bug first, then verified the fix. The full suite runs in a few seconds. That fast feedback loop is what makes the whole methodology work — you can regenerate, audit, fix, and verify in minutes, not days.

## What COBOL Gets Right
COBOL is a deeply unfashionable language. The syntax is verbose. The tooling is dated. Nobody writes new COBOL by choice.
But there is a reason it has survived in financial systems for 60 years, and it is not just institutional inertia. COBOL has two properties that matter enormously for banking.
First, fixed-point decimal arithmetic. COBOL does not have floating-point numbers. You declare `PIC S9(13)V99` and you get a signed number with 13 integer digits and 2 decimal places. Arithmetic on these fields is exact. There is no 0.1 + 0.2 = 0.30000000000000004 problem. Money is stored and computed exactly as dollars and cents, because the language was designed for exactly this.
Second, the ON SIZE ERROR clause. Every arithmetic operation can include an ON SIZE ERROR handler that fires if the result exceeds the field's capacity. This is not an exception. It is not a trap. It is an explicit, in-line control flow branch that keeps the original field value intact and lets you handle the overflow however you want. In VAULT-CBS, every balance-mutating operation uses this to prevent silent corruption at the $99 trillion boundary.
These are not features you appreciate until you have tried implementing the same thing in a language without them. In most languages, you would need a decimal library and manual overflow checks on every arithmetic operation. In COBOL, they are built into the language.
## What I Learned
Building a core banking system taught me a few things.
The reason these systems are hard to replace is not the language. It is the accumulated domain logic. Thousands of edge cases in how money moves, how dates work, how regulations interact, how errors propagate, how audit trails must be maintained. A rewrite in any language still has to implement all of this, and the people who understand all the rules are the same people who have been maintaining the COBOL for decades. I wrote about this in [Backwards Compatible for Life](/backwards-compatible-for-life.md).
Banking is not a technology problem. It is a regulatory compliance problem with a technology implementation. Every feature I built was shaped more by the relevant regulation than by any technical constraint. Reg CC determined hold calculation. Reg D determined transfer limits. Reg E determined dispute timelines. BSA/AML determined transaction monitoring thresholds. The code is just the regulation in executable form.
But the biggest takeaway is about methodology, not banking. [Verification](/verification-is-the-bottleneck.md) is everything. Writing the initial 25 modules took a fraction of the total effort. The other 85% was audit, testing, and fixing the interactions between those modules. If I had stopped after the initial build, I would have had a system that looked complete but silently corrupted money in edge cases.
The gap between "works on the happy path" and "handles real-world inputs correctly" is enormous. In traditional development, you close that gap by writing code carefully. In Regenerable Implementation, you close it by writing specs and tests carefully, and then letting agents regenerate the code until the tests pass. The care moves from the implementation to the verification. I think that shift is going to define how serious software gets built with AI agents.
The code is on [GitHub](https://github.com/NSEvent/cobol-banking-system). All 32,000 lines of it.